
티스토리 뷰
N+1쿼리를 방지하기 위해 rails AR에서 제공하는 4가지 association data load 방법을 정리해보자.
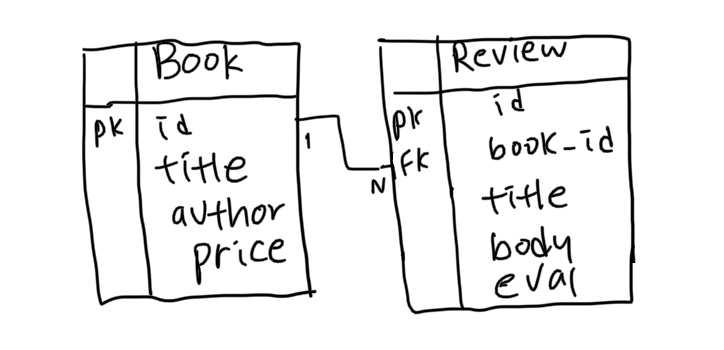
joins
이름처럼 SQL join 쿼리로 변환된다. joins = inner join, left_outer_joins = left outer join
SQL join에서 되는 건 다 된다. where, group, having, select...
특히 다른 로드 방식과 비교해서 select나 group 사용해서 원하는 대로 custom한 쿼리를 작성하고 싶을 때 쓴다.
irb(main):003:0> result = Book.joins(:reviews).where(reviews: {eval: :good}).group(:author).select("books.author, COUNT(*) as count").order(author: :asc)
Book Load (2.7ms) SELECT books.author, COUNT(*) as count FROM `books` INNER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` WHERE `reviews`.`eval` = 0 GROUP BY `books`.`author` /* loading for inspect */ ORDER BY `books`.`author` ASC LIMIT 11
=> #<ActiveRecord::Relation [#<Book id: nil, author: "김금희">, #<Book id: nil, author: "무라카미 하루키">, #<Book id: nil, author: "버지니아 울프">]>result.each do |r|
puts "#{r.author} #{r.count}"
end
# author count
# 김금희 2
# 무라카미 하루키 3
# 버지니아 울프 1
*nested join
다른 로드 방식에서도 이런식으로 쓸 수 있다.
Author.joins(books: [{reviews: { customer: :orders} }, :supplier] )
author
|_ book
|_ review
| |_ customer
| |_ order
|_ supplier
*sql join이 n개의 테이블을 엮어서 가상의 테이블을 만드는 느낌 ? 이라면 아래에 소개되는 방식들은 기본적으로는 Book 레코드를 가져오되 연관 테이블의 레코드도 같이 가져와서 메모리에 적재해둔다 (굳이 비유하자면 캐싱)의 관점으로 받아들이면 맞을 것 같다.
따라서 가져온 연관 데이터에 대한 접근 방식도 결이 다른데,
join은 주로 select절에서 적어준 alias로 각 속성 값을 가져온다면 다른 로드 방식은 모델에서 has_many, belongs_to로 정의한 연관 메소드를 통해서 참조한다.
result = Book.joins(:reviews).select("books.author, COUNT(*) as cnt")
book1 = result.first
book1.cnt
# preload, eager_load, includes
result = Book.includes(:reviews)
book1 = result.first
book1.reviews.length
eager_load
irb(main):007:0> result = Book.eager_load(:reviews)
SQL (0.8ms) SELECT DISTINCT `books`.`id` FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` /* loading for inspect */ LIMIT 11
SQL (1.2ms) SELECT `books`.`id` AS t0_r0, `books`.`title` AS t0_r1, `books`.`author` AS t0_r2, `books`.`price` AS t0_r3, `reviews`.`id` AS t1_r0, `reviews`.`book_id` AS t1_r1, `reviews`.`title` AS t1_r2, `reviews`.`body` AS t1_r3, `reviews`.`eval` AS t1_r4 FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` WHERE `books`.`id` IN (1, 2, 3, 4, 5, 6, 7) /* loading for inspect */
=> #<ActiveRecord::Relation [#<Book id: 1, title: "양을 쫓는 모험", author: "무라카미 하루키", price: 10000>, #<Book id: 2, title: "1973년의 핀볼", author: "무라카미 하<Book id: 3, title: "댄스 댄스 댄스", author: "무라카미 하루키", price: 12000>, #<Book id: 4, title: "너무 한낮의 연애", author: "김금희", price: 12000>, #<Book id: 5,r: "김금희", price: 13000>, #<Book id: 6, title: "댈러웨이 부인", author: "버지니아 울프", price: 15000>, #<Book id: 7, title: "자기만의 방", author: "버지니아 울프", price: 15000>]>eager_load의 연관데이터 메모리 적재 방식은 LEFT OUTER JOIN이다. (preload의 경우 각 테이블에서 개별로 select 쿼리로 가져온다) 따라서 preload와 다르게 books테이블이 아닌 reviews 테이블에 대한 where절도 쓸 수 있다.
irb(main):014:0> result = Book.eager_load(:reviews).where(reviews: {body: '메롱'})
SQL (0.7ms) SELECT DISTINCT `books`.`id` FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` WHERE `reviews`.`body` = '메롱' /* loading for inspe */ LIMIT 11
SQL (0.5ms) SELECT `books`.`id` AS t0_r0, `books`.`title` AS t0_r1, `books`.`author` AS t0_r2, `books`.`price` AS t0_r3, `reviews`.`id` AS t1_r0, `reviews`.`book_id` AS t1_r1, `reviews`.`title` AS t1_r2, `reviews`.`body` AS t1_r3, `reviews`.`eval` AS t1_r4 FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` WHERE `reviews`.`body` = '메롱' AND `books`.`id` = 7 /* loading for inspect */
=> #<ActiveRecord::Relation [#<Book id: 7, title: "자기만의 방", author: "버지니아 울프", price: 15000>]>
# result.length
# 1
left_outer_joins와의 차이점이라면 Book을 기준으로 cartesian product한 결과를 내놓기 때문에 결과 row 수가 Book보다 많아지는 (1:n관계라면) SQL의 left outer join과 다르게
preload는 연관데이터를 조회해서 메모리에 적재해두는 방식이 left outer join인거지 결국 결과물로 내놓는 것은 Book의 레코드이기 때문에 row개수가 늘어나거나 그렇지 않다.
# left_outer_joins
irb(main):017:0> result = Book.left_outer_joins(:reviews)
Book Load (0.6ms) SELECT `books`.* FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` /* loading for inspect */ LIMIT 11
=> #<ActiveRecord::Relation [#<Book id: 1, title: "양을 쫓는 모험", author: "무라카미 하루키", price: 10000>, #<Book id: 1, title: "양을 쫓는 모험", author: "무라카미 하루키d: 2, title: "1973년의 핀볼", author: "무라카미 하루키", price: 10100>, #<Book id: 3, title: "댄스 댄스 댄스", author: "무라카미 하루키", price: 12000>, #<Book id: 4, title:금희", price: 12000>, #<Book id: 5, title: "경애의 마음", author: "김금희", price: 13000>, #<Book id: 5, title: "경애의 마음", author: "김금희", price: 13000>, #<Book id: 6, author: "버지니아 울프", price: 15000>, #<Book id: 7, title: "자기만의 방", author: "버지니아 울프", price: 15000>]>
# result.length
# 9
# vs
# eager_load
irb(main):020:0> result = Book.eager_load(:reviews)
SQL (0.6ms) SELECT DISTINCT `books`.`id` FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` /* loading for inspect */ LIMIT 11
SQL (0.4ms) SELECT `books`.`id` AS t0_r0, `books`.`title` AS t0_r1, `books`.`author` AS t0_r2, `books`.`price` AS t0_r3, `reviews`.`id` AS t1_r0, `reviews`.`book_id` AS t1_r1, `reviews`.`title` AS t1_r2, `reviews`.`body` AS t1_r3, `reviews`.`eval` AS t1_r4 FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` WHERE `books`.`id` IN (1, 2, 3, 4, 5, 6, 7) /* loading for inspect */
=> #<ActiveRecord::Relation [#<Book id: 1, title: "양을 쫓는 모험", author: "무라카미 하루키", price: 10000>, #<Book id: 2, title: "1973년의 핀볼", author: "무라카미 하루키"id: 3, title: "댄스 댄스 댄스", author: "무라카미 하루키", price: 12000>, #<Book id: 4, title: "너무 한낮의 연애", author: "김금희", price: 12000>, #<Book id: 5, title: "경애ice: 13000>, #<Book id: 6, title: "댈러웨이 부인", author: "버지니아 울프", price: 15000>, #<Book id: 7, title: "자기만의 방", author: "버지니아 울프", price: 15000>]>
# result.length
# 7
그리고 eager_load 에서는 group이 안된다.
https://github.com/rails/rails/issues/15854
뭔가 rails github 이슈에 올라온 글을 보면 eager_load에서 group이 제대로 작동하지 않는게 bug니까 고쳐야된다라고 하는 것 같은데
지금도 해보면 안된다. 뭐 잘 모르겠다..
irb(main):006:0> Book.eager_load(:reviews).group(:id)
SQL (1.6ms) SELECT `books`.`id` AS t0_r0, `books`.`title` AS t0_r1, `books`.`author` AS t0_r2, `books`.`price` AS t0_r3, `reviews`.`id` AS t1_r0, `reviews`.`book_id` AS t1_r1, `reviews`.`title` AS t1_r2, `reviews`.`body` AS t1_r3, `reviews`.`eval` AS t1_r4 FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` GROUP BY `books`.`id` /* loading for inspect */ LIMIT 11
Traceback (most recent call last):
ActiveRecord::StatementInvalid (Mysql2::Error: Expression #5 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'study_development.reviews.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by)
preload
각 연관 테이블에 가져온 레코드의 PK를 FK로 가지고 있는 레코드를 가져오라는 개별 쿼리를 날린다.
그렇게 미리 메모리에 적재해두고 has_many, belongs_to 등으로 정의한 메소드명?으로 참조했을때는 새로 db에 접근하는게 아니라 메모리에서 바로 찾아본다. (따라서 N+1 쿼리 발생을 방지 할 수 있음)
irb(main):022:0> Book.preload(:reviews)
Book Load (0.4ms) SELECT `books`.* FROM `books` /* loading for inspect */ LIMIT 11
Review Load (0.4ms) SELECT `reviews`.* FROM `reviews` WHERE `reviews`.`book_id` IN (1, 2, 3, 4, 5, 6, 7)
=> #<ActiveRecord::Relation [#<Book id: 1, title: "양을 쫓는 모험", author: "무라카미 하루키", price: 10000>, #<Book id: 2, title: "1973년의 핀볼", author: "무라카미 하루키"id: 3, title: "댄스 댄스 댄스", author: "무라카미 하루키", price: 12000>, #<Book id: 4, title: "너무 한낮의 연애", author: "김금희", price: 12000>, #<Book id: 5, title: "경애ice: 13000>, #<Book id: 6, title: "댈러웨이 부인", author: "버지니아 울프", price: 15000>, #<Book id: 7, title: "자기만의 방", author: "버지니아 울프", price: 15000>]>result.each do |r|
puts "#{r.author} #{r.title} #{r.reviews.length}"
end
# 무라카미 하루키 양을 쫓는 모험 2
# 무라카미 하루키 1973년의 핀볼 1
# 무라카미 하루키 댄스 댄스 댄스 1
# 김금희 너무 한낮의 연애 1
# 김금희 경애의 마음 2
# 버지니아 울프 댈러웨이 부인 1
# 버지니아 울프 자기만의 방 1단 eager_load와 다르게 메모리에 적재해두기 위해 db에서 조회하는 방식이 개별 쿼리를 날리는 것이기 때문에 Book(자기자신)이 아닌
다른 연관 테이블에 대한 where절은 사용할 수 없다.
irb(main):026:0> result = Book.preload(:reviews).where(reviews: {body: '메롱'})
Book Load (3.4ms) SELECT `books`.* FROM `books` WHERE `reviews`.`body` = '메롱' /* loading for inspect */ LIMIT 11
Traceback (most recent call last):
ActiveRecord::StatementInvalid (Mysql2::Error: Unknown column 'reviews.body' in 'where clause')
includes
평소에는 preload방식으로 동작하나 연관 테이블에 대한 where절과 함께 쓰이면 eager_load방식으로 동작한다.
# preload like..
irb(main):027:0> Book.includes(:reviews)
Book Load (0.4ms) SELECT `books`.* FROM `books` /* loading for inspect */ LIMIT 11
Review Load (0.4ms) SELECT `reviews`.* FROM `reviews` WHERE `reviews`.`book_id` IN (1, 2, 3, 4, 5, 6, 7)
=> #<ActiveRecord::Relation [#<Book id: 1, title: "양을 쫓는 모험", author: "무라카미 하루키", price: 10000>, #<Book id: 2, title: "1973년의 핀볼", author: "무라카미 하루키"id: 3, title: "댄스 댄스 댄스", author: "무라카미 하루키", price: 12000>, #<Book id: 4, title: "너무 한낮의 연애", author: "김금희", price: 12000>, #<Book id: 5, title: "경애ice: 13000>, #<Book id: 6, title: "댈러웨이 부인", author: "버지니아 울프", price: 15000>, #<Book id: 7, title: "자기만의 방", author: "버지니아 울프", price: 15000>]>
# eager_load like..
irb(main):028:0> Book.includes(:reviews).where(reviews: {eval: :bad})
SQL (0.5ms) SELECT DISTINCT `books`.`id` FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` WHERE `reviews`.`eval` = 1 /* loading for inspect */ LIMIT 11
SQL (0.4ms) SELECT `books`.`id` AS t0_r0, `books`.`title` AS t0_r1, `books`.`author` AS t0_r2, `books`.`price` AS t0_r3, `reviews`.`id` AS t1_r0, `reviews`.`book_id` AS t1_r1, `reviews`.`title` AS t1_r2, `reviews`.`body` AS t1_r3, `reviews`.`eval` AS t1_r4 FROM `books` LEFT OUTER JOIN `reviews` ON `reviews`.`book_id` = `books`.`id` WHERE `reviews`.`eval` = 1 AND `books`.`id` IN (2, 5, 7) /* loading for inspect */
=> #<ActiveRecord::Relation [#<Book id: 2, title: "1973년의 핀볼", author: "무라카미 하루키", price: 10100>, #<Book id: 5, title: "경애의 마음", author: "김금희", price: 130title: "자기만의 방", author: "버지니아 울프", price: 15000>]>
정리하자면 쿼리 속도로 따지면 preload(includes)가 join보다 훨씬 빠를테지만, join은 필요한 데이터만 select, 그루핑해서 가져올 수 있기 때문에 메모리 소모 측면에서는 join이 나을 것 같다.
(참고)
length vs count vs size
- count will perform an SQL COUNT query
- length will calculate the length of the resulting array
- size will try to pick the most appropriate of the two to avoid excessive queries
length ⇒ 메모리에 적재된 데이터 수 셈. 만약 모든 레코드가 메모리에 적재된 상황이라면 굳이 쿼리를 또 날릴 필요 없으니까 length 쓰기
count ⇒ SQL count 쿼리랑 동일
size ⇒ 위 두개 방법 믹스

이번에 프로젝트를 할 때의 모델이 이런식이었다. 이때 유저 수가 약 38만개 정도나 돼서 어차피 페이징처리로 10개만 보내줄건데 전체를 다 조인한뒤 10개를 자르니까 시간이 너무 오래걸려서 수정을 해야했다.
한참 연관쿼리는 다 조인으로만 처리할 때여서
def self.from_subquery(relation, subquery_alias)
from("(#{relation.to_sql}) as #{subquery_alias}")
.order("#{subquery_alias}.#{primary_key}")
end처음에는 유저 모델에 이런식의 클래스메소드를 정의한뒤에, 저 relation 자리에 10개만 조회하는 서브쿼리를 넣어 인라인뷰처럼 동작하게 하고
이 앞뒤로 select절, join절을 체이닝하는 식으로 orm으로 복잡한 from절 서브쿼리를 꾸역꾸역 표현해서 코드를 짜놨다.


시간이 확실히 줄긴 했어도 너무 복잡했는데, 나중에 수정할 때 생각해보니까 그냥 페이징처리 한다음에 includes (preload)를 쓰면 되는 거였다! 🤯
일단 limit 10으로 유저 10개만 가져오고, 그 다음 개별 쿼리에서 FK를 이 10개 PK 중에서 가지고 있는 유저만 가져온다.
훨씬 간단하고 다른 사람도 이해하기 편한 코드가 되었다.
그런데 일단 10개를 가져온 뒤 연결된 유저가 있다면 누군지 표시해주는게 요구사항이라 이렇게 할 수 있었지만,
만약 연결된 유저가 있는 것 중에서 10개를 잘라야 했다면 다른 방식을 찾아봐야 할 것 같다.
그리고 알고보니 프로젝트에 goldiloader라는 Gem이 적용되어 있었는데 알아서 어느정도 알아서 eager_load 해주는 gem인가보다.
https://github.com/salsify/goldiloader
By default all associations will be automatically eager loaded when they are first accessed so hopefully most use cases should require no additional configuration
* lazy load란?
First, AR uses proxy objects to represent queries, and only replaces them with result sets when you call a method like all, first, count, or each. This design is also what enables us to build queries via chained calls.
- <understanding rails eager-loading> by jmc
result.class
=> ActiveRecord::Relation클래스를 찍어보면 아직 Relation이고, 실제 db에 접근하는 것은, find, all, first, count 같은 명령을 내릴때인 것 같은 동작 방식..?
그래서 체이닝식으로 적어줄 수 도 있는 것이다.
(그런데 딱 이걸 부르는 명칭이 lazy load인지는 확실치 않다)
* has_many :through vs has_and_belongs_to_many
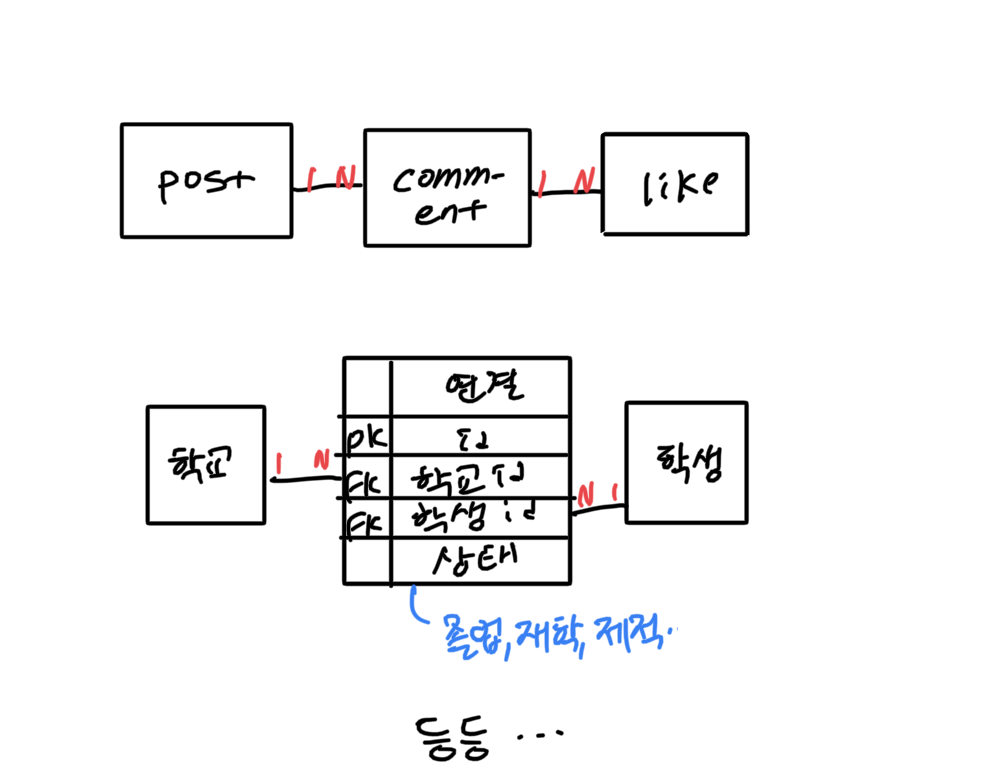
has_many는 1:n이든, n:m이든 대응되는 모델을 가진 테이블들(실질적으로 through: 뒤에 적어주는 것은 테이블명이 아니라 다른 has_many 등으로 정의한 연관관계명 이다) 을 통해서 여러개를 가지고 있음을 표현한다.
특히 has_many :through를 통해 표현한 n:m관계에서는 조인테이블이 독립적인 모델 객체와 대응되므로 상태 같은 추가 칼럼을 가지거나, validation, callback도 가능하다.
class School < ApplicationRecord
has_many :connections
has_many :students, through: :connections
end
class Connection < ApplicationRecord
belongs_to :school
belongs_to :connection
end
class Student < ApplicationRecord
has_many :connections
has_many :schools, through: :connections
end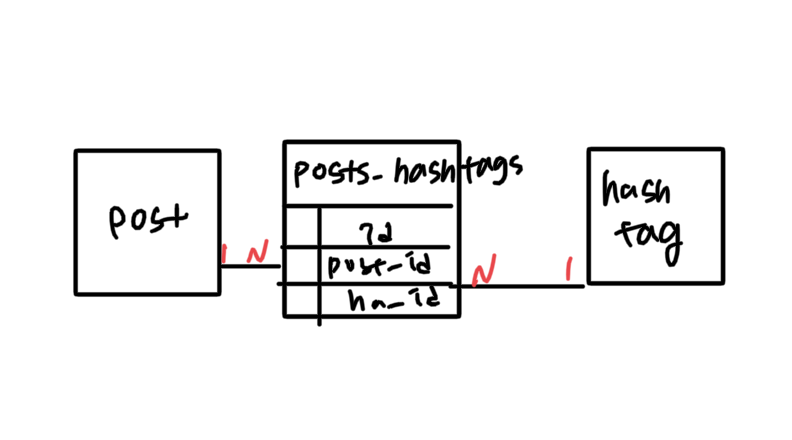
n:m 관계를 간단히 표현하고 싶을 때 사용하고, 중간 테이블은 orm 상에서 대응되는 모델 클래스가 없다.
물론 마이그레이션 파일을 통한든, 직접 db에서 만들든 조인 테이블 생성은 해줘야 한다.
보통 조인테이블 이름은 두 클래스명을 _로 연결하는 식으로 지어진다.
Active Record creates the name by using the lexical order of the class names. So a join between author and book models will give the default join table name of "authors_books" because "a" outranks "b" in lexical ordering
class Post < ApplicationRecord
has_and_belongs_to_many :hashtags
end
class Hashtag < ApplicationRecord
has_and_belongs_to_many :posts
end
[ 참고하면 좋은 글 ]
A Visual Guide to Using :includes in Rails
'시리즈 > Ruby' 카테고리의 다른 글
| omniauth로 rails app에 oauth2 인증 추가하기 (0) | 2023.03.22 |
|---|---|
| Rails 스케줄링 방식 비교 (0) | 2022.08.05 |
| sidekiq으로 job을 batch 묶음으로 실행하기 (0) | 2022.08.05 |
| 루비 block, lambda, proc (0) | 2022.01.23 |
| 사이드킥 (0) | 2021.11.12 |