
티스토리 뷰
Rebalancing
카프카 파티션을 consumer 인스턴스에 고르게 재분배하는 과정!
크게 2-step으로 이루어짐.
(1) group management (membership)
- active 컨슈머 인스턴스 리스트업
(2) resource assignment
- 파티션 분배해주기
그리고 각 스텝의 책임자가 다름.
(1) coordinator (broker 중 하나)
- heartbeat 받고, 리밸런싱 트리거하는 주체 (파티션이나 컨슈머에 변경 감지하면)
(2) group leader (consumer 중 하나)
- 일반적으로 가장 먼저 조인한 consumer가 리더가 됨. partition assignment strategy 정하고 수행하는거 담당.

cf) 그럼 controller는 뭔가??
zookeeper => metadata store (저장소) 및 controller 선출
controller => control plane. 브로커 노드 중 하나에 위치
리밸런싱 개선 히스토리
자료들을 읽다보니까 그간 리밸런싱 관련해서는 2번 정도의 큰 개선이 있었던 듯...??
(이 내용들이 뭔지는 아래에서 설명)
Improvement 1) 파티션 분배를 client-side에서 수행하라
- JoinGroupResponse에서 분배결과를 바로 알려줬던 것에서 => group 멤버 리스트를 알려주는 것으로 바꿈.
- 파티션 배분은 그룹 리더 (consumer)가 하고 coordinator에게 알려줌.
- [버전 0.9즈음]
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Client-side+Assignment+Proposal
tl;dr
이렇게 한 이유는
- 책임분리 (coordinator: group management / group leader: assignment)
- 브로커 (클러스터) 리부팅 없이 적용할 수 있음.
- 클라이언트가 원하는 커스텀 분배 알고리즘도 가능
- 드물지만 한 그룹내 같은 파티션 여러번 중복 배분이 필요한 클라이언트 케이스도 있을 수 있으니
단점도 있음
- coordinator가 partition owner를 모르기 때문에 offset commit이 정당한 컨슈머로부터 오는건지 검증 불가능.
(근데 redundant 파티셔닝 가능하게 하려면 감수할 수 밖에 없음)
- assignment 디버깅 하기가 좀 까다로워짐.
Improvement 2) stop-the-world를 개선하라
- 리밸런싱 퍼포먼스를 개선
- [버전 2.4부터] incremental cooperative rebalance protocol 도입
tl;dr2
23년 11월 기준 latest release는 3.6.0이고
로컬 개발용으로 사용중인 카프카 버전은 확인해보니 3.4임

3.6 document 보면 디폴트 파티션 분배 전략은 [RangeAssignor, CooperativeStickyAssignor] 라고함.
문서에 따르면 EAGER -> COOPERATIVE 방식으로 바꾸려면 consumer 설정에서 Assignor (파티션 분배 방식)를 cooperative-stikcy만 남겨두고 (RangeAssignor지우고) 롤링업데이트 하면 된다는 것 같은데... 모르겠당
consumer 정보 출력해보면 (밑에있음) 디폴트 RangeAssignor로 설정되어 있음.


동작 방식
(리밸런싱 과정만 본다면 2-phase)
1.Collect membership, subscriptions and additional metadata for every consumer in the group
2. Decide on a new partition assignment and propagate it to every consumer in the group
1. findCoordinator
consumer가 consumer group 조인하려고 아무 브로커한테나 coordinator 브로커 endoint 물어보기.
찾기 => hash(group.id) % #partitions
2. joining the group (join group)
- [JoinGroupRequest] all consumers -------> coordinator : 멤버 리스트 취합
- [JoinGroupResponse] coordinator --------> consumers : 리더에게 멤버 리스트 알려줌.
(리더 아닌 일반 conusmer에게는 안알려줌. 비워서 전달)
3. 파티션 분배하고 결과 공유하기 (sync group)
- 리더가 'PartitionAssignor' 인터페이스를 구현한 알고리즘에 따라서 파티션 분배
- [SyncGroupRequest] consumers (leader만 값 채워서) -----> coordinator : 분배 결과 알려줌
- [SyncGroupResponse] coordinator ------> consumers : 결과 공유
Assigment Strategy
- Range
- Round Robin
- Sticky (rond robin에서 기존 할당을 최대한 유지하도록 개선)
- cooperative sticky
4. 멤버 상태 tracking
- 파티션 - conusmer 매핑에 변경 정상적으로 consuming 하는 phase. (stable group)
coordinator는 다시 리밸런싱을 트리거해야하는지 주시하고 있어야 함.
- heartbeat
=> coordinator에게 consumer가 나 살아있으니까 그룹에서 빼지 말라고 생존신고
- offset commit
=> 파티션 여기까지 처리 완료함.
이 파티션 처리자가 다른 컨슈머로 바껴도 이 정보를 보고 거기서부터 처리 시작할 수 있음.
5. 리밸런싱이 필요함 알리기
consumer는 다음과 같은 응답을 받으면 리밸런싱 phase구나... 를 알아차리고 다시 joinGroup 요청을 보냄
- HeartbeatResponse가 REBALANCE_IN_PROGRESS로 왔을 때
- CommitOffset 응답이 REBALANCE_IN_PROBRESS로 왔을 때
리밸런싱할 때마다 group generation은 +1 됨.
consumer group 정보 출력

kafka-topics --bootstrap-server localhost:9094 --topic order --describe
리밸런싱 언제 Trigger?
- consumer join / leave
- consumer가 너무 오랫동안 idle할 때 / network failure
- 파티션 추가 되었을 때
hearbeat.interval.ms => 얼마나 자주 heartbeat 보낼건지 (3ms)
session.timeout.ms => 얼마나 오래 heratbeat을 안보내도 리밸런싱이 일어나지 않는지. (10ms)
max.poll.interval.ms => polling 안해서 죽었다고 간주되기 시작하는 시간.
heartbeat는 background 스레드에서 보내니까, 폴링하는 메인 스레드가 데드락 걸리거나 그랬을 수도 있어서 이것도 고려함.
State-machine
coordinator
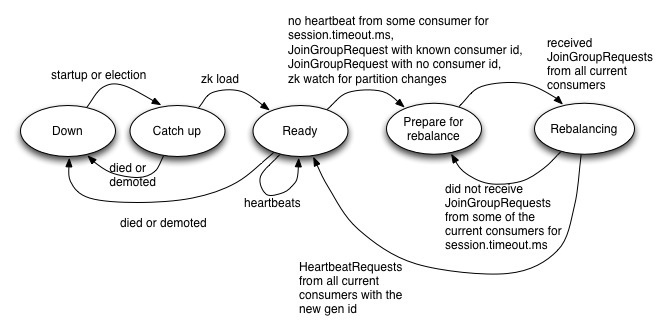
consumer group (coordinator가 상태관리)
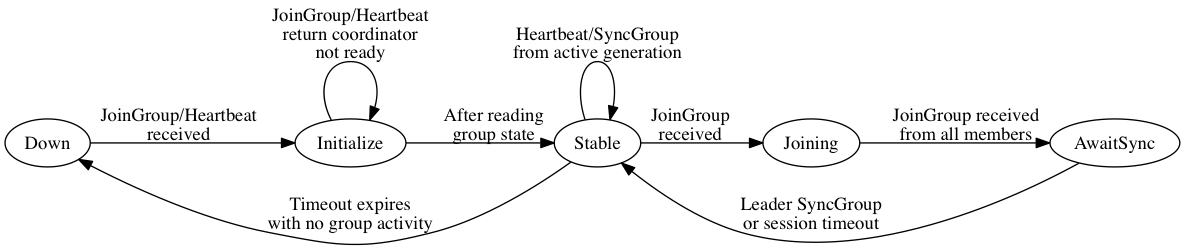
consumer (각 멤버)
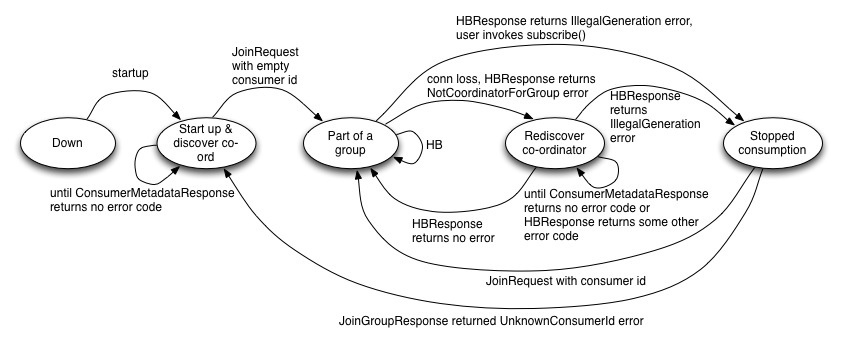
Offset & Commit
재분배후 consumer 인스턴스가 어디부터 다시 처리하면 될지 확인.
이 과정에서 중복처리, 처리 안함 케이스가 발생할 여지가 많아서 잘 따져봐야함.
- CommitOffsetRequest
(근데 보통은 명시적으로 안하고 auto commit 방식을 많이 쓴다고 함.)
- OffsetFetchRequest
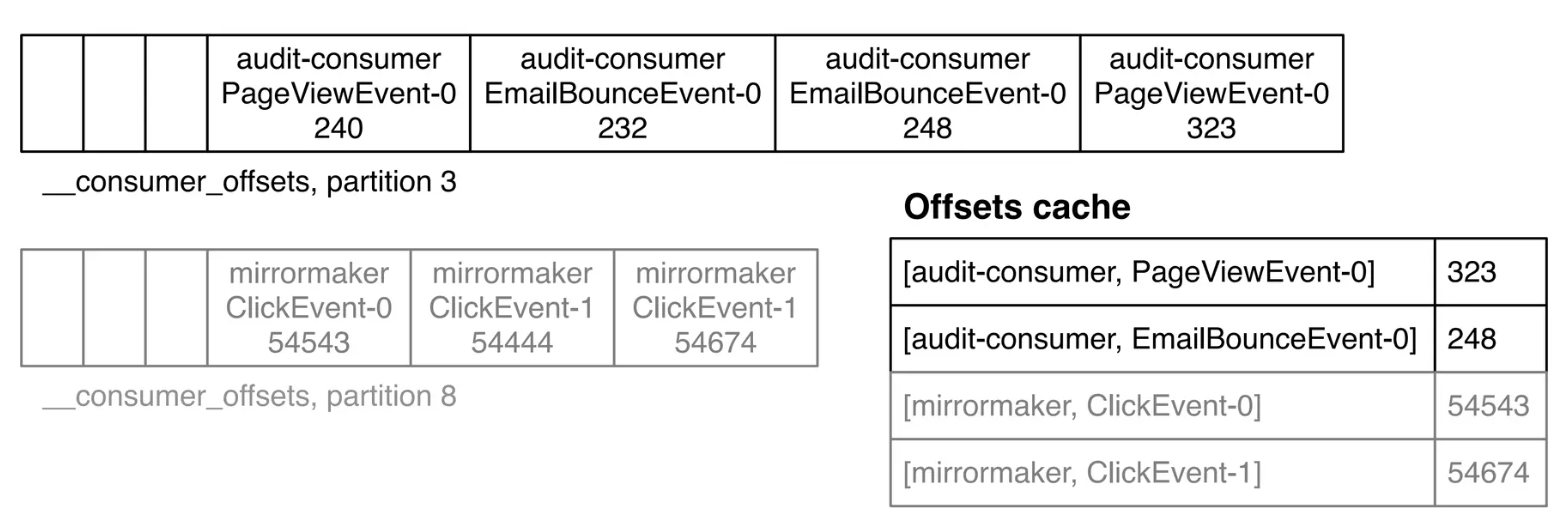
consumer가 polling한 레코드들 처리하고 난 다음에, 정상적으로 처리한 가장 마지막 offset 번호를 __consumer_offsets 토픽에 produce
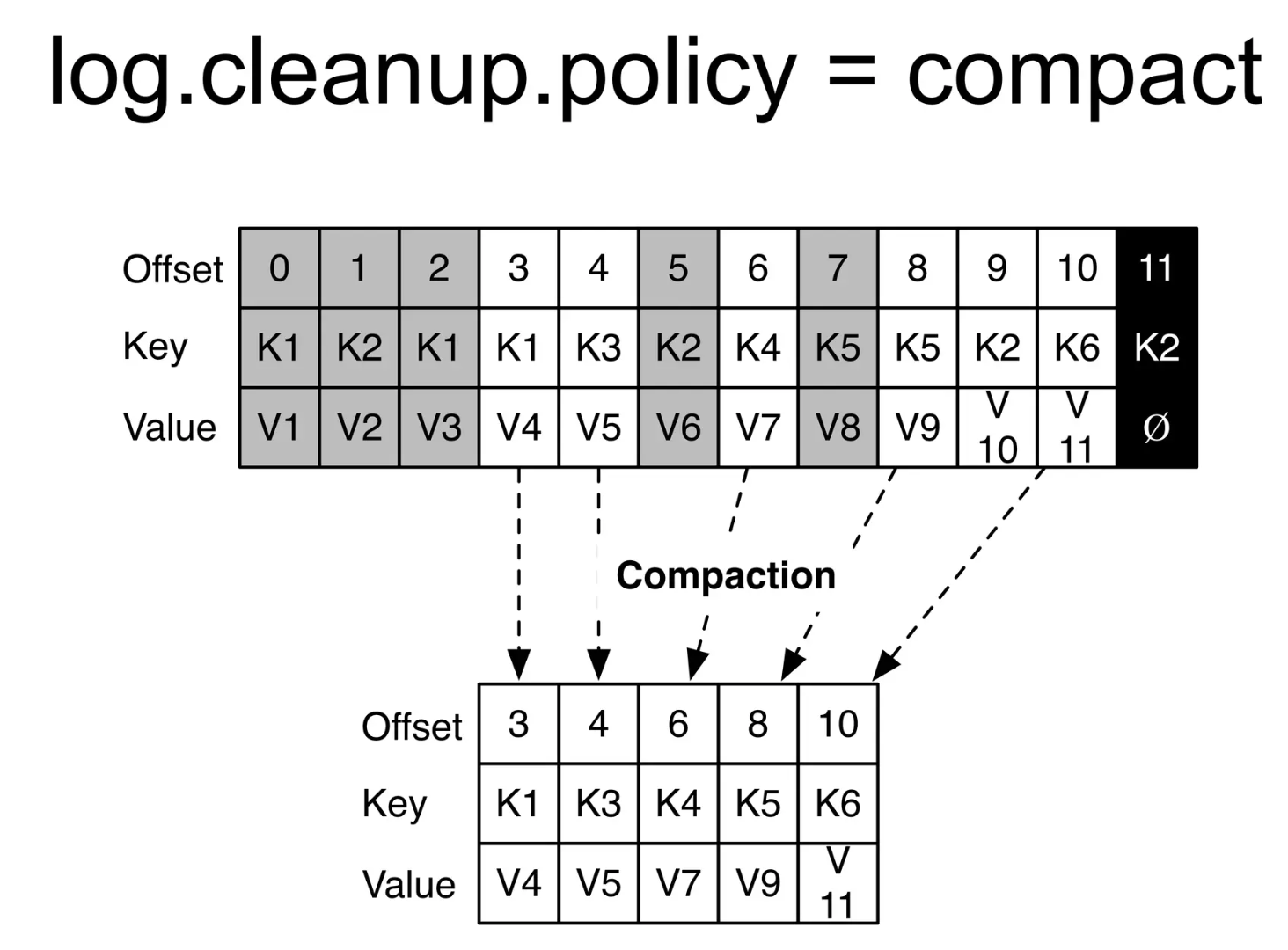
이 로그들을 주기적으로 GC도 함.
__consumer_offsets 토픽 출력해보기

kafka-console-consumer --bootstrap-server localhost:9092 --topic __consumer_offsets \
--formatter 'kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter' \
--partition 0 --from-beginning# 출력 예시
[my-group-id-14,fruit-prices,1]::OffsetAndMetadata(offset=5497, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1619425537926, expireTimestamp=None)
[my-group-id-14,fruit-prices,0]::OffsetAndMetadata(offset=3550, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1619425553694, expireTimestamp=None)
key : <consumer_group>,<topic>,<partition>
value : <offset>,<partition_leader_epoch>,<metadata>,<timestamp>
(참고용)
토픽 정보 출력하기

kafka-topics --bootstrap-server 127.0.0.1:9092 --topic user-events --describe
Topic:user-events PartitionCount:3 ReplicationFactor:3 Configs:min.insync.replicas=2,cleanup.policy=compact,segment.bytes=1073741824,retention.ms=172800000,min.cleanable.dirty.ratio=0.5,delete.retention.ms=86400000
Topic: user-events Partition: 0 Leader: 101 Replicas: 101,100,104 Isr: 101
Topic: user-events Partition: 1 Leader: 104 Replicas: 104,101,102 Isr: 104,101,102
Topic: user-events Partition: 2 Leader: 102 Replicas: 102,100,103 Isr: 102,100,103
⚠ 확인해 볼 부분
내가 생각하기론 이 '파티션 분배'와 관련해서 다음과 같은 정보들을 저장하고 있어야 할 것 같은데,, (어디에???)
- 그룹에 어떤 멤버가 있는지
- 어떤 멤버 (conusmer)가 어떤 파티션을 처리하고 있는지 매핑 정보
- 각 파티션이 어디까지 처리 되었는지 => __consumer_offsets 토픽에 저장
위의 2개 같은 정보들은 zookeeper랑 coordinator가 가지고 있고. 기존 coordinator 죽어서 새로 뽑히면, zookeeper에서 그룹 메타데이터 다시 로드해오는 그런건가??

비효율 개선
1. static group membership
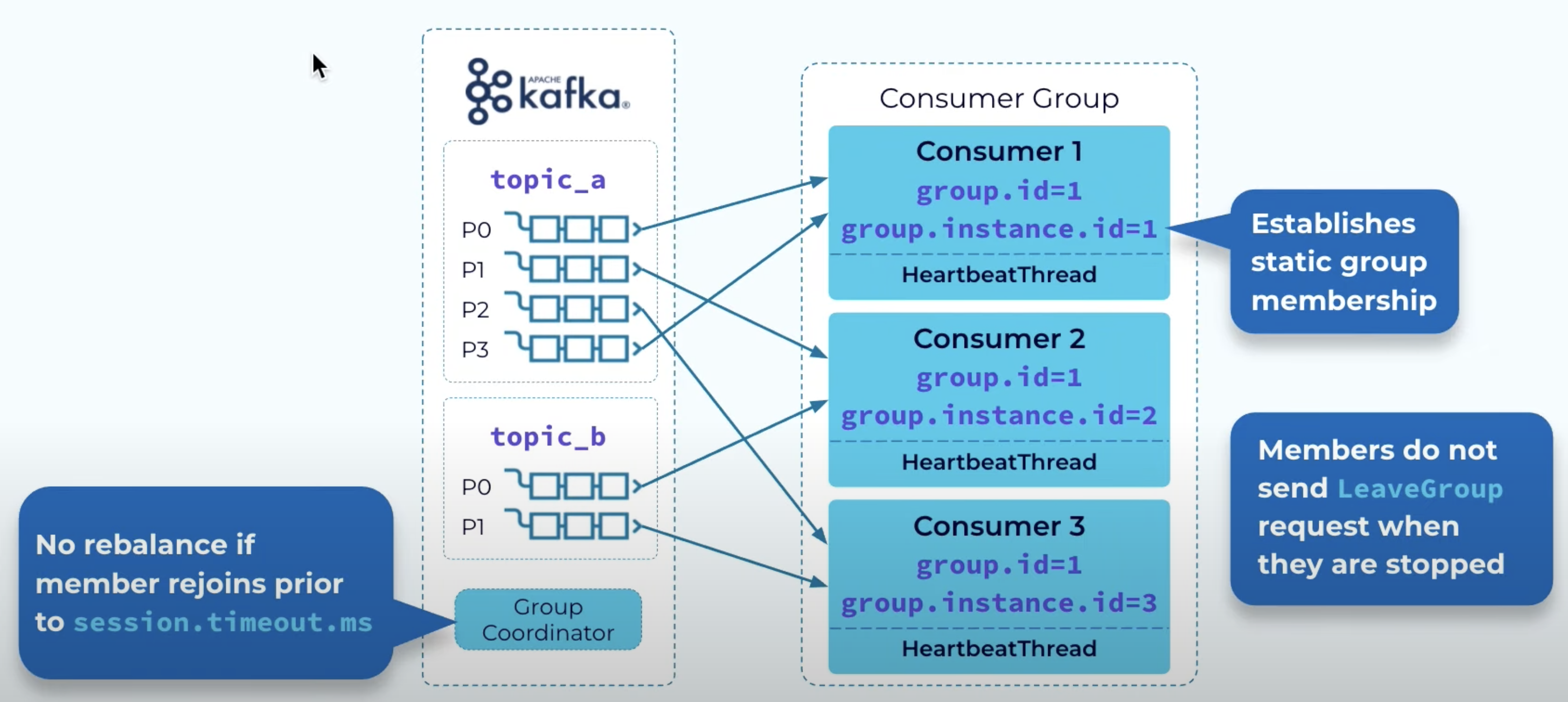
어떤 컨슈머가 잠깐 리부팅할 건데 (멤버십, 할당에 변경 필요 x) 그때마다 다시 리밸런싱하면 비효율.
- 잠깐 멈추는 동안 LeaveGroup 요청 보내지 않고, coordinator도 세션 타임아웃 기간동안은 리밸런싱 트리거 안시킴.
2. Cooperative Rebalancing
기본적으로 이전의 카프카는 리밸런싱하는 동안은 해당 그룹의 모든 멤버가 파티션 점유를 놓고 컨슈밍 작업을 중단하는 방식으로 동작.
(pause processing)
=> 이게 stop-the-world 라는 카프카에서 개선이 필요함이 논의되는 현상..!
그래서 개선된 CooperativeStickyAssignor 같은 분배 strategy를 사용하면 전체 pause가 아닌 점진적으로 일부 서브셋에서만 리밸런싱 할 수도 있다함.
2 types of Rebalancing protocol
Eager
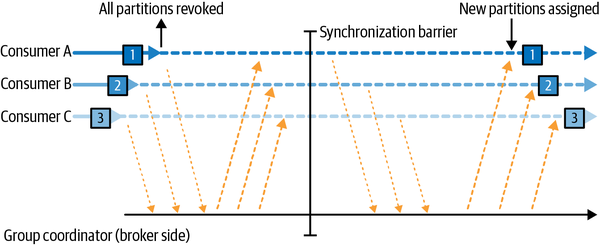
모든 consumer pause 하고 재할당. (여태까지는 기본적을 이렇게 동작했음)
Coordinate
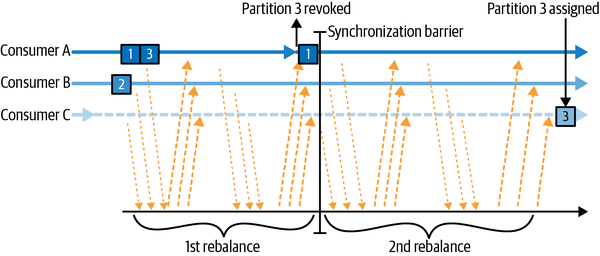
일부 멤버들만 점진적으로 재할당 phase에 해당하고, 나머지는 컨슈밍 작업 계속할 수 있음.
parallel consumer
https://github.com/confluentinc/parallel-consumer
- confluent사에서 작성한 consumer 라이브러리.
- 파티션을 늘리지 않고도 컨슈머단에서 동시 처리량을 늘릴 수 있게 해줌
파티션 개수 늘리는 것의 단점 여기 네이버 d2글을 참조

- 메세지키 기준으로 동일 스레드가 처리 (순서보장) [더 정확히는 partition / key / unordered 3가지 방식 제공]
- 아마 키네시스의 KCL (kinesis client library)도 이렇게 비슷하게 구현이 되어있나본지, 같은 샤드에 publish된 두개의 메세지가 한 컨슈머 어플리케이션 내에서 다른 두 스레드가 동시에 처리하는 걸 봄. (파티션키가 다름.) => 파티션키를 같게 만들어주자 같은 스레드에서 순차 처리됨.
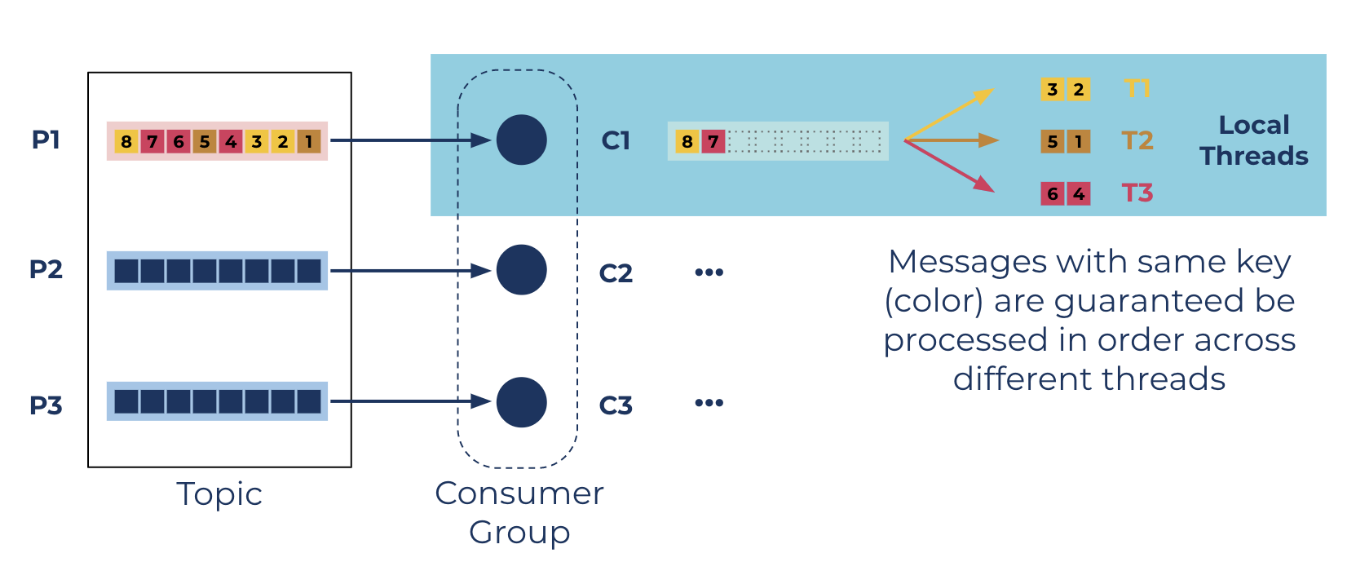
- 여기서 (d2블로그) 소개하는 라이브러리의 '오류로 인한 중복처리 방지' 기능도 흥미로운 것 같다 (이런 패턴은 항상 비슷하게 고민하게 되는 듯)
(요약하자면)
offset 4,5,6,7을 가져와서 처리하던 중 4,6,7만 처리 완료. 서버 장애로 5번 처리 못함.
__consumer_offsets 토픽에는 4번까지 처리완료 했다고 커밋.
그럼 서버 재시작했을 때 6,7 번이 중복 처리 되지 않는가???
라이브러리 내부 메타데이터에 (디스크 같은데 저장하나??) incompleteOffsets = 5 / completedOffsets = 6,7 번이라고 저장해두고
이미 처리한건 스킵.
References
요약으로 보기 좋음
https://redpanda.com/guides/kafka-performance/kafka-rebalancing
https://developer.confluent.io/courses/architecture/consumer-group-protocol/
https://www.confluent.io/blog/apache-kafka-data-access-semantics-consumers-and-membership/
kafka confluence
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Client-side+Assignment+Proposal
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+0.9+Consumer+Rewrite+Design
세션 발표
https://www.youtube.com/watch?v=MmLezWRI3Ys&t=366s
consumer offset
https://www.naleid.com/2021/05/02/kafka-topic-partitioning-replication.html
https://www.slideshare.net/jjkoshy/offset-management-in-kafka
kafka-definitive-guide ch04
https://www.oreilly.com/library/view/kafka-the-definitive/9781492043072/ch04.html
parallel consumer
https://www.confluent.io/blog/introducing-confluent-parallel-message-processing-client/
'시리즈 > Stream Processing' 카테고리의 다른 글
| 이벤트 스트림 parallel processing (kafka, kinesis, axon) (1) | 2023.11.19 |
|---|---|
| Kinesis Lease (1) | 2023.11.19 |
| mysql 쿼리 처리 방식 - 스트리밍 vs 버퍼링 (0) | 2022.12.10 |
| iterable, iterator 그리고 generator (0) | 2022.08.08 |
| iterator 패턴 (0) | 2022.07.31 |